- Published on
Convolutional Neural Network | 卷…积神经网络的应用
- Authors

- Name
- Jiaqi Wang(Ramis)
[ 最后更新 于 2025-4-21 22:34 ]
无助的拖延患者正在强迫自己把CNN写完…(嗷嗷大哭中
说到CNN,就绕不开街景识别。 这也可能是我本人学习的东西和神经网络最直接关联的地方。虽然还完全没有抽时间练习一个街景识别的小项目,但是还是先按着头逼自己把这篇文章写了。
1. 图像拆解的基本方法
之前我们所讨论过的CNN解决的图像分类问题,涉及到的只是非常浅的方面——就是回答这个图片包含的是什么物体?比如说,狗,房子,人。而这个其实简单的神经网络甚至逻辑回归都是可以完成的(经典的手写数字问题就可以不使用CNN来回归)。
然而,图像中承载的信息非常多。这就需要更深度的学习来拆解和认识图像中潜藏的信息,或者说,“让机器读懂图片”。于是,我们就有了目标定位和语义分割这两种途径去更进一步获取图片中的信息。
- 目标定位(Object localization) 回答: 👉 “图像中的物体在哪里?” 它不仅要判断是什么,还框出它的位置。比如下面我们就圈出了狗狗,自行车和车。

- 而语义分割(Semantic segregation) 则更进一步地回答👉 “这个像素是什么”。它将图片的每一个像素都分入不同的分类,从而获取图片的每个部分是什么,如下图所示,图片就按照不同类别:交通牌,行人,地面,车行道,车,天空,树木,房屋被划分清楚了。

2. 目标识别 Object Localisation的实现方法
2.1. 对图像进行网格划分
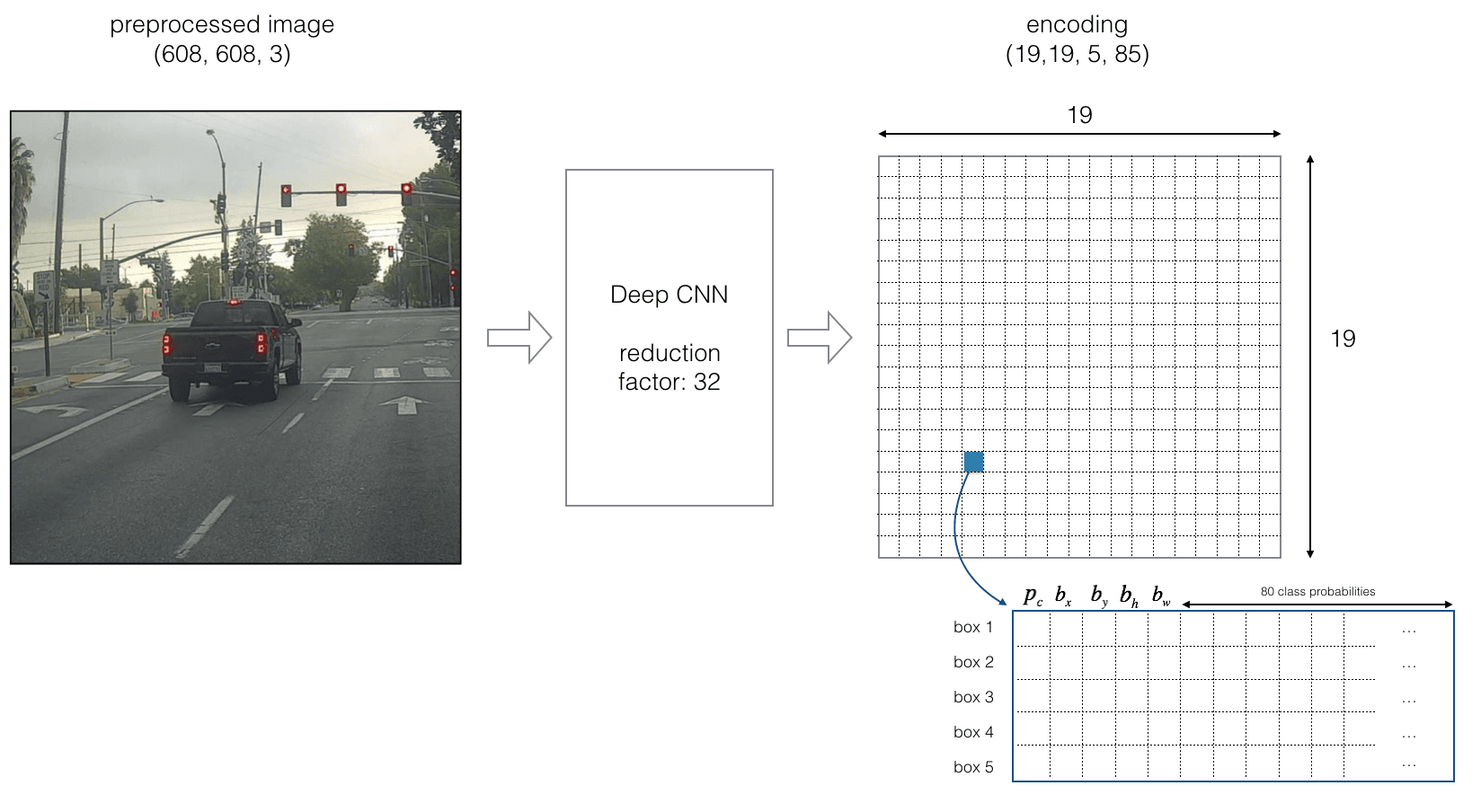
为了更快速的枚举每个可能的“定位框框”,一般不考虑采用像素为基本单元,而是把图片分为更大块的网格:如下图就是把图片分成了19×19。
2.2 定义boundingbox
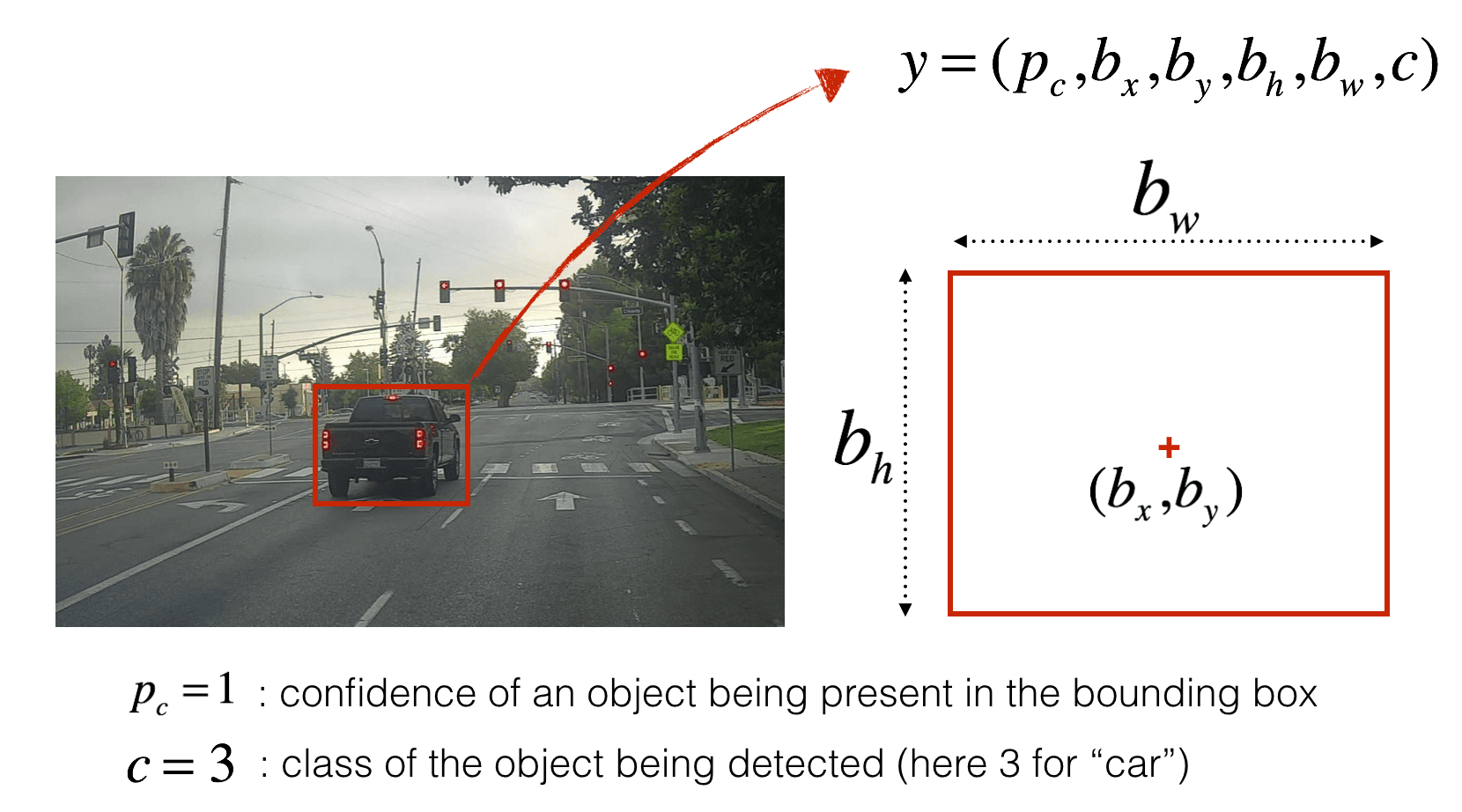
不同尺寸的bounding box
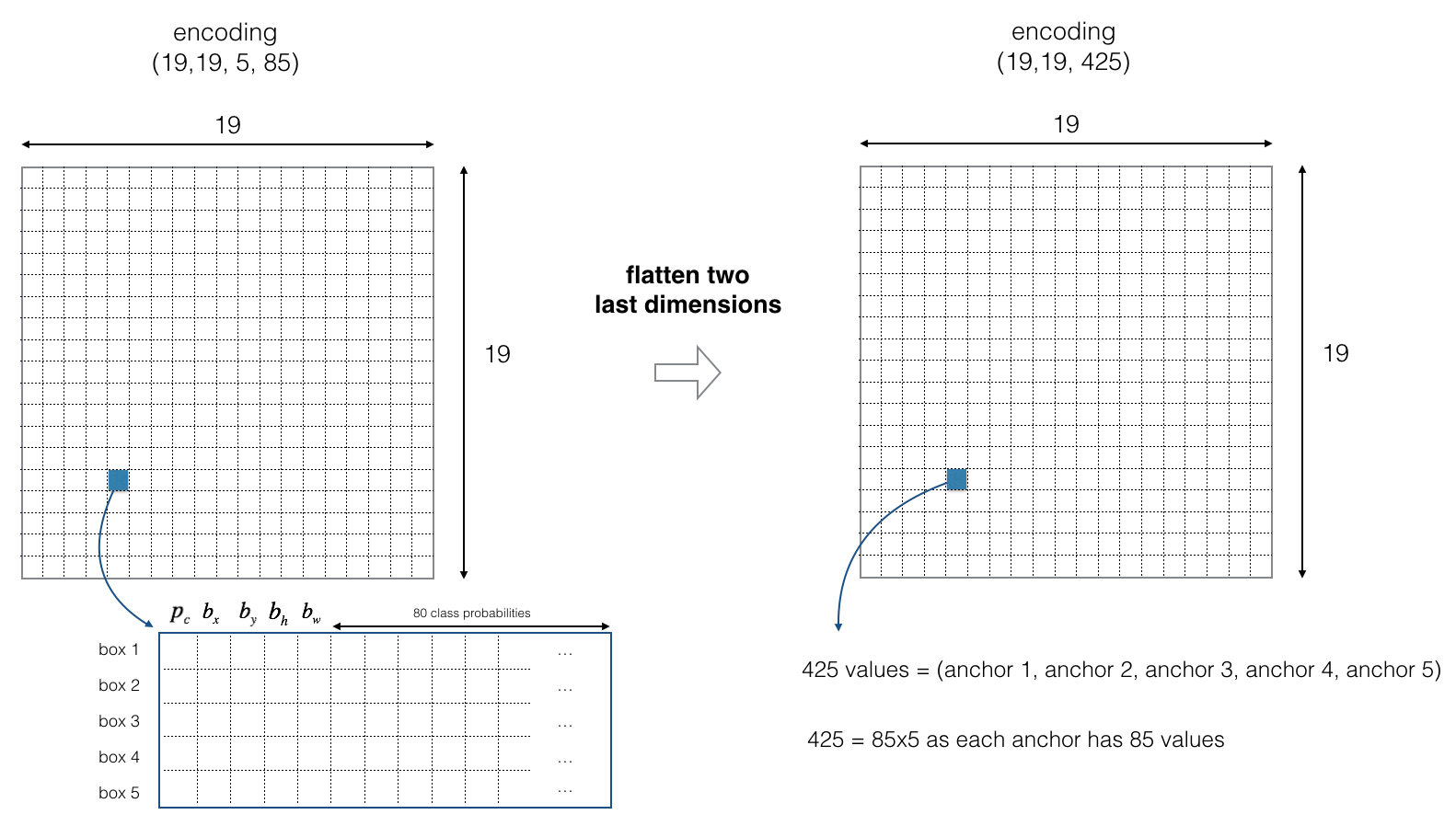
2.3 重新定义输出层
对于输出层,每一个boundingbox需要记录的是对于每一个class分别的概率。

2.4 重复识别怎么办?
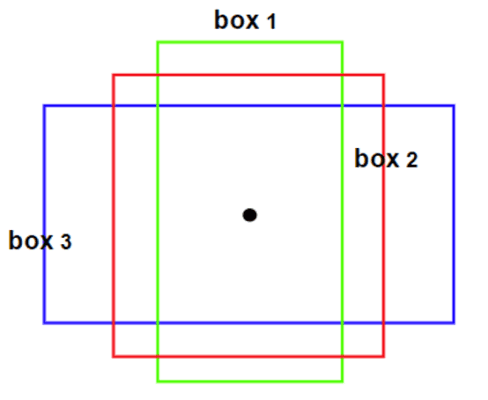
然而,还有一个重要的问题需要解决,那就是如果一辆车被重复记录在了不同的boundingbox里,该怎么去重呢?
这就需要用到一个重要的函数:IoU (Intersection over Union)来检测不同框框的重叠程度。
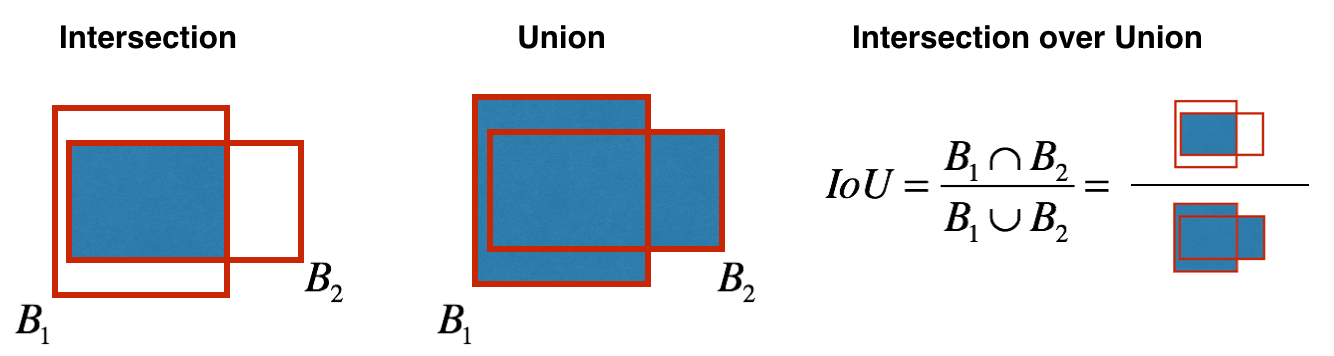
这里我们用non-max supression来压缩层。不同于以往简单的提取最大值,这里需要进行的是两个步骤:
- 首先我们需要去掉概率低的框框,无论是由于没有识别到物体还是不能够很确定是某一类物体。这里往往需要预先设置一个阈值,比如60%以下就过滤掉。
- 然后对于剩下的框框,我们要先选出出现物体概率最大的框,然后确定它识别出来的最可能的类别后,我们计算它和余下所有检测到相同类的框框的重叠程度,将这其中重叠率高的(同样需要设置阈值)删除。
- 一直重复上面这一步,直到没有可以删除的框框了,就得到了预测的结果。

附图:YOLO第一次发表时的架构:
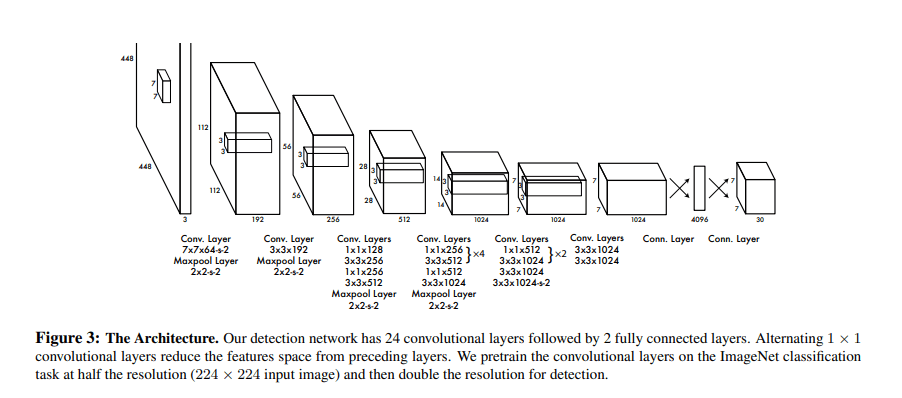
从这个架构里可以看出,以上所说的所有的框框重叠以及每个class的概率问题都是对于最后输出层。而之前的架构和之前的分类用到的CNN并没有很大的差异。
3 语义分割(Semantic Segmentation)的实现
以我浅显的理解,我把semantic segmentation的过程看作是先模糊再锐化的过程。
如下图这个U-Net的经典架构,前半段下沉,是从一个个像素到达抽象的“语义”,也就是物品的类别信息这个层级,再之后,又从下往上 从语义上反推回各个像素该有的类别。
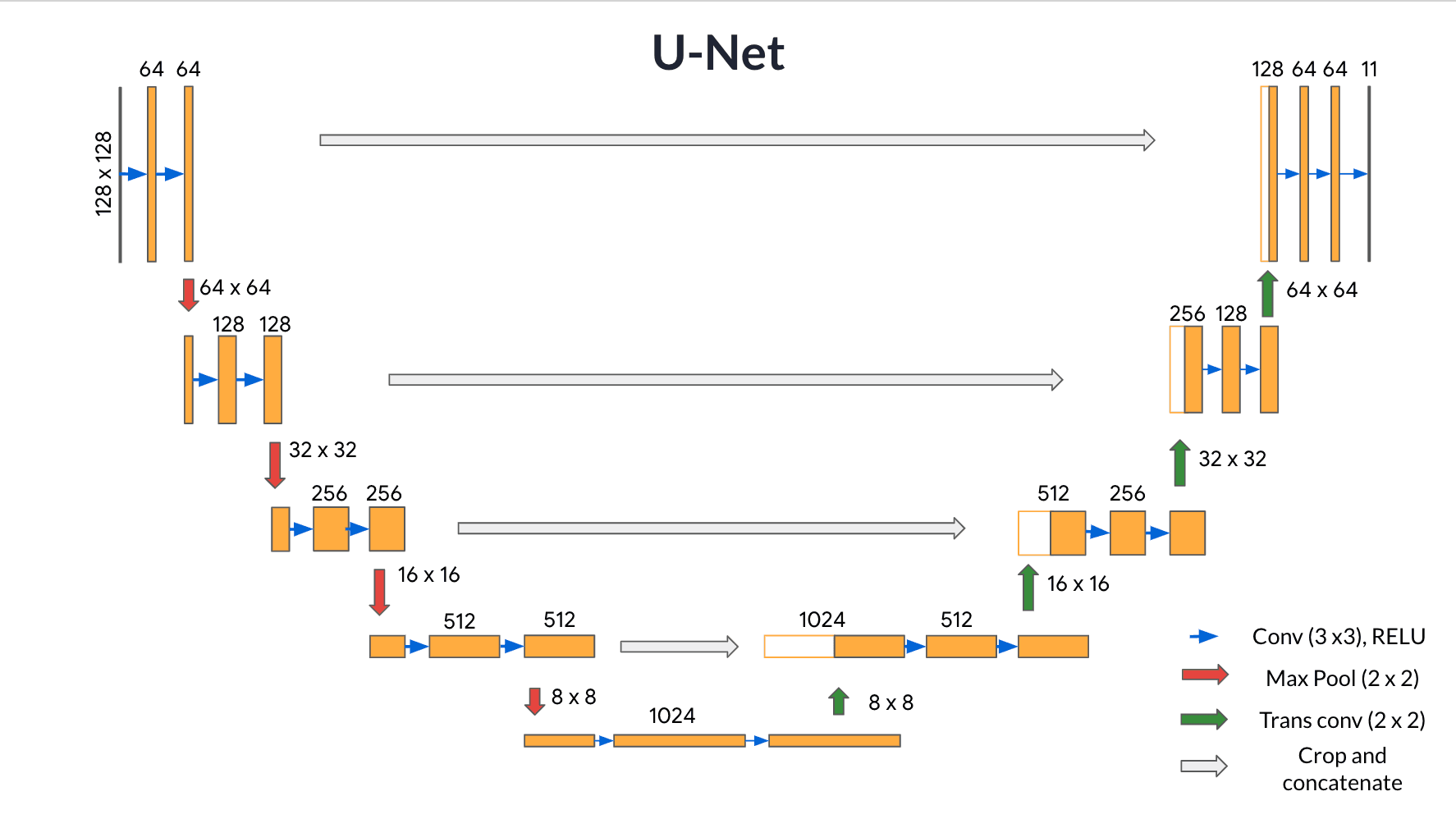
Encoder- Convolutional Layers 编码器部分
上图左半边下沉的部分,也就是编码器部分。它通常由多个卷积层(Convolutional layers)和池化层(Pooling layers)组成,我们也可以把它当作是普通的CNN。和其他的识别和分类类似,它通过一系列的卷积层,逐步提取图像中的高级语义特征,或者说是全局的特征,而不会受到局部细节的干扰。(我们可以理解为如果我们只需要图像的类别,那么做到这里其实已经有了所需的信息。)
但是如果想要精确到每一个像素,我们就必须再多做接下来这半段:
Decoder - Transpose Convolution 解码器部分
在这后半段,解码器通过一系列的transposed Convolution(反卷积或转置卷积)将编码器得到的低分辨率特征图逐步恢复到原始图像的尺寸(有一种锐化的感觉)从而得到精准的分割图。
- 反卷积层/转置卷积:这些层的作用是通过上采样操作将特征图的空间分辨率逐渐增大,同时将特征图的尺寸恢复到原始输入图像的大小。 这里的过程也采用不同的filter进行scan,可以理解为卷积的逆过程——只不过是由小图扩大变成大图的过程。以下两张图分别显示了有无stride的区别,蓝色是输入层,蓝绿色是transpose的输出结果。 这样使得高维度的特征图恢复到与原始图像相同的分辨率。
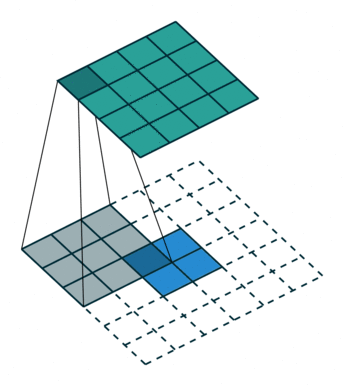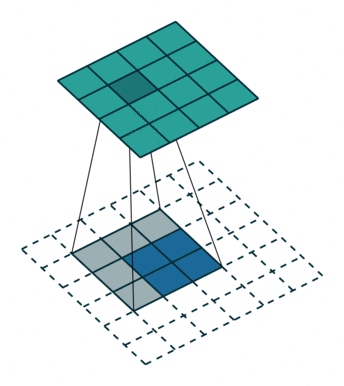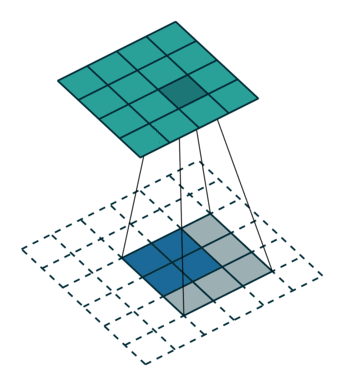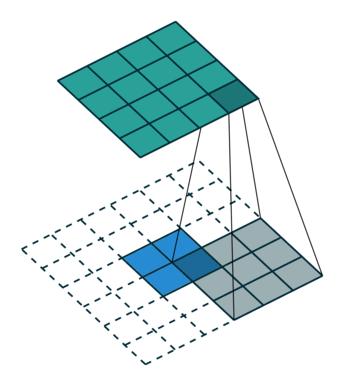
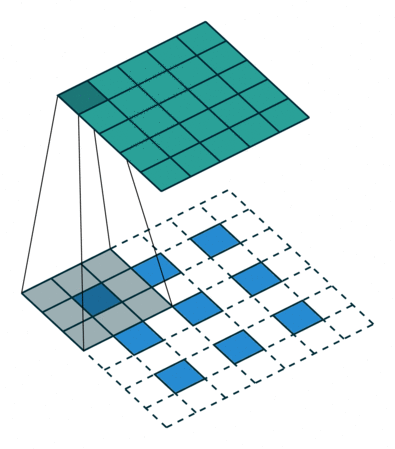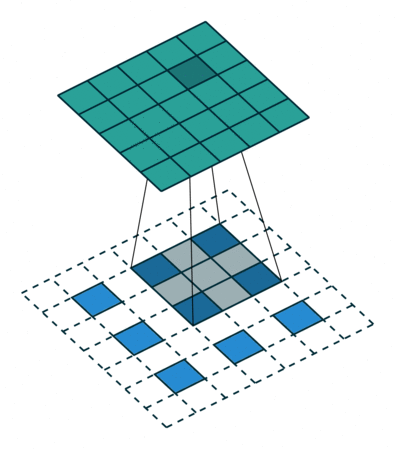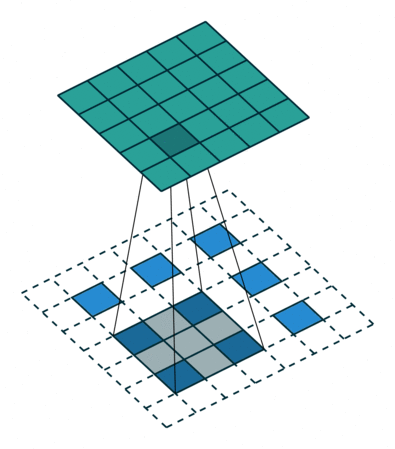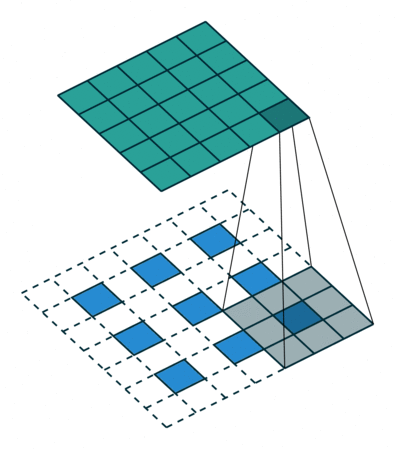
- 跳跃连接(Skip Connections,或者也就是图片中的crop and concatenate):在每一步的上采样过程中,解码器会利用编码器之前相应层的特征图(通过跳跃连接)进行拼接(concatenate),从而不仅使用压缩的高层语义信息,还能借助高分辨率的局部细节进行扩图,这样可以确保解码器在生成分割结果时能保留细节(如边缘),而不是仅依赖高级语义信息。

写在后面
之后可能会写一个实践操作的帖子(在此埋坑)。因为这样写理论还是有点抽象,实际操作才能加深理解吧。不过最近手头上要学的东西太多,实践项目排期大拥堵…还没有顾上哦。
感觉把CNN总结结束后,想写一些轻松的帖子。这两章写的有点太痛苦了,可能是自己真的对神经网络的兴趣没有那么大吧。感觉整个体系都非常极端和暴力的堆砌算力和数据。架构其实好像就跟挖矿一样在碰运气。唔。希望下个单元终于来到大语言模型会有机会做出一些好玩点的小项目。
我也不知道。可能最近C#那边写了很多有意思的东西(应该有机会是也是要记录一下的),所有整个神经网络这些学的就很慢了。不过最近想插空再研究一下self-organizing-map以及它和Kmean的比较以及结合(再度挖坑)。看来五月要做的事情很多呀。嘿嘿。
-鹅仔 2025/04/21 01:53