- Published on
算法入门 | 图的遍历 和 双端队列
- Authors

- Name
- Jiaqi Wang(Ramis)
[ 最后更新 于 2024-04-21 ]
图论是学习数据结构和算法绕不过的东西。——不重要的鹅仔
广度优先搜索 BFS vs 深度优先搜索DFS
核心思想和区别
深度优先搜索(DFS)和广度优先搜索(BFS)都是针对图的搜索/遍历算法。 其不同之处首先在于它们分别使用栈和队列来记录搜索过程。BFS所查询到的路径通常是最短路径,因为它逐层遍历,而DFS则不一定。DFS的优势则在于其能够自然地与递归、栈相结合。
在时间复杂度方面,DFS通常能更快地查询到离根节点更远的目标结点,BFS则能更快地覆盖更多的分支。空间复杂度上,BFS需要更多的内存空间来存储搜索过程中的节点,而DFS通常空间开销较小。这些特点和应用场景使得DFS和BFS在不同的问题中发挥着各自的优势。
过程解析之BFS
BFS的搜索过程需要维护一个队列,每次搜索队头所在的结点,将与其联通的、且还未被查询的结点放入队列,完毕后将队头移出队列。以此反复执行直到队列为空——也就是所有结点都被搜索到了了。
看下面的例子: 1.我们从A结点开始搜索,先将A放入队列 2.将与A联通的 BCD也放入队列,之后A可以出队,并标记为explored 3.此时队头变为B,沿着B查询到EF,EF入队,B出队 4.C变为队头,由于F已经位于队列中,于是将与其联通的G加入队列 5.之后在队头D由于没有新节点,查询无果、出队 6.此时E变为队头,搜索到H,H进队,E出队。 7.之后的所有在队中的结点已经搜寻不到新节点,按照顺序,依次出队。 8.此时队列为空,查询结束。

BFS延伸:无向图的联通问题
求一个无向图的联通部分有几个(如下图):

只需要循环调用每一个未被搜索过的结点,从其开始BFS,将所有搜索到的结点标记为一个连通块:
for each i in n:
if v(i) unexplored: BFS(G,i) ->从i结点开始BFS;连通块数量+1
过程解析之DFS

在深度优先搜索中,我们需要维护的是一个栈(当然有时可以直接以递归调用的形式来实现):
首先,A结点入栈,虽然连接到了BCD三个结点,但是直接沿着B结点(入栈)进行下一步搜索;
进入B结点后,也继续沿着和B相连的第一个不在栈中的结点E(入栈)搜索,然后一步步搜到H、F、C、G。(为了展现其和BFS的不同,这个例子有点极端)。当搜索到G结点时,已经没有新的结点可以入栈。此时开始依次出栈。由于返回的每一层都没有更新的结点加入,所以CFHEB全部出栈。此时,回到A结点,发现A结点还有相邻的D结点没有被搜索,于是D入栈。D入栈后也没有新节点,D出栈,A出栈。搜索全部结束。可以看到,如果在BFS中,D结点作为直接和A相连的结点应该在第一层搜索中就会入队,但是在DFS中却最后一个才被搜到,这就是DFS和BFS不同的打开方式了——DFS有点像把第一个套娃一直拆到最小的一个再开下一个套娃。
DFS延伸:拓扑排序问题
针对有向图,根据图中不同点的联通关系进行排序的全部可能(想象成大学选课中一些课是另一些课的先修课,求上完培养计划可行的课程安排):
可以注意到,深度优先搜索所形成的路径天然就符合拓扑排序的要求
参与搜索的有向图不可以有环,否则没有解
思路:那么对于无环的有向图,可以找到至少一个sink vertex(出度为0的点/不知道中文怎么翻译)(否则可以证明必有环路),假设找到了一个顶点v,为sink vertex,那么将f(v)记为n,然后将v顶点取出图,再对图内剩余的部分:'G-{v}' 进行向上回溯
主程序:
->首先标记all nodes unexplored
->current-label=n(记录当前排列的顺序)
for each v in G:(对于图内的每一个顶点)
if v not explored->DFS(G,v) 开始搜索
def DFS(G,start_v):
将此时的start_v标记为explored
对和start_v相连的每一个顶点,如果还未搜索过,再次调用dfs(G,v)
令f(s)=current_label (运行到此代表已经找到叶子节点/sink vertex, 出栈,当前顶点即为排序末置位)
->current_label-1(次序向前移动,再返回栈的上一层)

Deque in Python
在Python里标准库collections里有一个Deque(Double-ended Queue)类,Deque提供了与列表类似的方法,但是在两端插入和删除操作上的效率更高,可以很好地实现栈 、队的维护。
以下是deque类的一些常见用法:
- 创建deque:可以通过
collections模块导入并创建deque对象:
from collections import deque
# 创建一个空的deque
d = deque()
d = deque([1, 2, 3, 4, 5])
- 插入和删除操作:
deque支持从两端进行插入和删除操作来模拟栈/队两种数据结构
`# 从左侧插入元素
d.appendleft(0)
# 从右侧插入元素
d.append(6)
# 从左侧删除元素
d.popleft()
# 从右侧删除元素
d.pop()
- 索引和切片:
deque也同样支持与列表相同的索引和切片操作:
# 获取索引为i的元素
elem = d[i]
# 获取索引为start到end-1的切片
sublist = d[start:end]`
- 长度和清空:可以使用
len()函数获取deque的长度,并使用clear()方法清空deque中的所有元素:
# 获取deque的长度
length = len(d)
# 清空deque
d.clear()
实战:求根到叶子结点组成的所有数字之和
问题描述:
You are given the root of a binary tree containing digits from 0 to 9 only. Each root-to-leaf path in the tree represents a number.
- For example, the root-to-leaf path
1 -> 2 -> 3represents the number123.
Return the total sum of all root-to-leaf numbers. Test cases are generated so that the answer will fit in a 32-bit integer.
A leaf node is a node with no children.
Example 1:
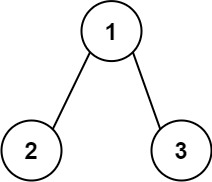
Input: root = [1,2,3] Output: 25 Explanation: The root-to-leaf path 1->2 represents the number 12. The root-to-leaf path 1->3 represents the number 13. Therefore, sum = 12 + 13 = 25.
Example 2:
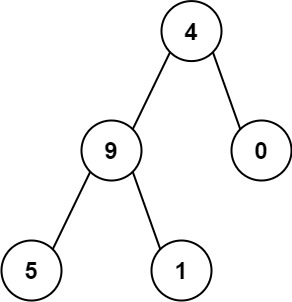
Input: root = [4,9,0,5,1] Output: 1026 Explanation: The root-to-leaf path 4->9->5 represents the number 495. The root-to-leaf path 4->9->1 represents the number 491. The root-to-leaf path 4->0 represents the number 40. Therefore, sum = 495 + 491 + 40 = 1026.
Constraints:
- The number of nodes in the tree is in the range
[1, 1000]. 0 <= Node.val <= 9- The depth of the tree will not exceed
10.
(虽然没怎么看到有人在用BFS做这道题,但是为了练习,采用了BFS和DFS两种算法求解: 其实效率上BFS似乎更快一些(只花了7 ms)
深度优先搜索(递归调用):
建立了一个leafsum的函数来求当前(子)二叉树的所有数字和,参数为当前所求的二叉树和其祖先节点上的数字和。
1.如果不是叶子结点:其值为leafsum(左子树,根节点值+祖先值* 10)+leafsum(右子树,根节点值+祖先值* 10) 2.如果是叶子节点:直接返回祖先值* 10+当前节点值
class Solution(object):
def sumNumbers(self, root):
"""
:type root: TreeNode
:rtype: int
"""
def leafsum(root,parentval):
if root.left and root.right:
return(leafsum(root.left,parentval*10+root.val)+leafsum(root.right,parentval*10+root.val))
elif root.left:
return(leafsum(root.left,parentval*10+root.val))
elif root.right:
return(leafsum(root.right,parentval*10+root.val))
else:
return(parentval*10+root.val)
return leafsum(root,0)
````
#### 广度优先搜索实现:
在用BFS实现中,采用deque来维护了一个队列:
```` class Solution(object):
def sumNumbers(self, root):
"""
:type root: TreeNode
:rtype: int
"""
sum=0
q = deque([(root,0)]) #维护队列q,以元组的方式存储:(当前树,和其祖先结点上的数字值)
while q: #当q不为空开始循环:
node,currentsum = q.popleft() #取队头的元素/同时使其出队
currentsum=currentsum+node.val #更新当前结点组成的数字:从祖先中继承的current sum值+结点本身的值,
if (not node.left) and (not node.right): #如果是叶子结点,那么currentsum就是所寻找的叶子节点所形成的数字,将最终结果的sum值更新
sum=sum+currentsum
else: #如果不是叶子结点,将其左子树右子树分别入队,并记录当前值乘以十(因为要整体向左移动一位)
if node.left:
q.append((node.left,(currentsum)*10))
if node.right:
q.append((node.right,(currentsum)*10))
return sum
结语
这周开始看图论,当然是从DFS和BFS开始,虽然算法比较直观,但是在使用时维护队列和堆栈还有不少需要注意的地方。也制作了几个ppt小动画来帮助自己/大家理解。由于在写leetcode时,二叉树已经被预设为了一个class,所以没有数据存取方面的困扰,但是实际上对于图/树的存储还是有不少需要复习的地方,给自己标记一个to do。下周应该要继续把强连通图问题看完然后接下来再复习最短路算法和其他图论上的东西。
-鹅仔 2024/4/21 19:51

原文存档于我的上一个Notion博客,今天抽空把本篇日志汇总至此。 鹅仔 -2024/5/26